Город снежных фигур на Комете
Немного фотографий:
Немного фотографий:
Просто немного фотографий:
Небольшой хинт по настройке автодополнения адресов из адресной книги LDAP в Thunderbird:
Если коротко, в расширенных настройках создать строковое свойство:
ldap_2.servers.[ADDRESSBOOK].autoComplete.filterTemplate
Где [ADDRESSBOOK] - индивидуально для каждой книги.
со значением примерно такого вида:
(|(mozillaNickname=%v*)(cn=%v*)(sn=%v*)(mail=%v*)(displayName=%v*))
Проблема:
*, то нужно вводить как \*Более подробно: не получается слинковать только при указании свойства caps у appsink или вставки между
videoconvert и
appsink фильтра
capsfilter с нужным форматом. Но об этом подробнее под катом.
Кросс-компиляция в Meson достаточно проста. Выполняется, как и в CMake при помощи вспомогательного файла:
[host_machine]
system = 'linux'
cpu_family = 'aarch64'
cpu = 'aarch64'
endian = 'little'
[binaries]
c = 'aarch64-linux-gnu-gcc'
cpp = 'aarch64-linux-gnu-g++'
#ld = 'gold'
ar = 'aarch64-linux-gnu-ar'
strip = 'aarch64-linux-gnu-strip'
pkgconfig = 'pkg-config'
#exe_wrapper = 'wine' # A command used to run generated executables.
[properties]
c_args = ['-DCROSS=1', '-DSOMETHING=3']
c_link_args = ['-some_link_arg']
sys_root = '/some/path'
Сохраняем его под именем cross-build.ini и передаём meson:
mkdir build
cd build
meson --cross-file ../cross-build.ini ..
Стоит отметить, что meson ОЧЕНЬ чувствителен к значениям переменных типа CC ,CXX и LD. Он рассчитывает, что если они установлены, то они отсылают к компилятору, который генерирует код для билд-машины, иными словами - нативный код. Это актуально для среды LTIB, которая настраивает окружение таким образом, что эти переменные окружения ссылаются на кросс-компилятор. Для случая autotools и большинства случаев использования CMake - это нормально. А вот Meson может сломаться.
Ещё одной особенностью является задание линкёра - ld = xxx. Он не задаёт конкретный бинарник, а отсылает к типу: gold (бинарник ld.gold или аналогичный), bsf (ld.bsf или аналогичный). Я задал его некорректно изначально, и только запуск Meson под strace позволил выяснить причину его недовольства.
Есть два поведения для большого количества вкладок:
Путь Google Chrome и производных: максимально сжимаем вкладки (правда потом они не отображаются и приходится неочевидным способом прокручивать колесиком мыши или горячими клавишами):
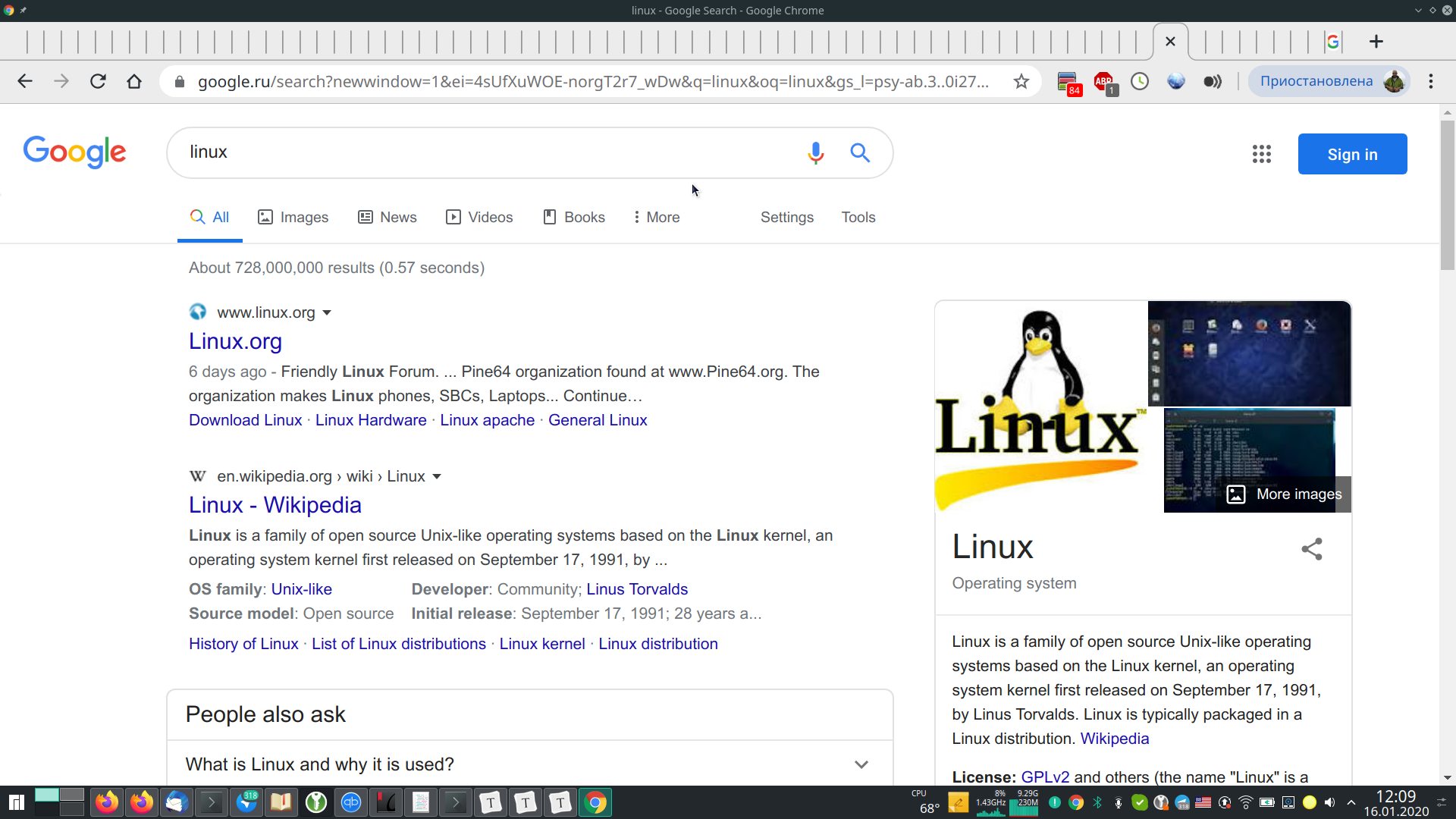
Путь Firefox: заполнять вкладками всё пространство, как будет занято, начинать их сжимать, если размер достигнут какого-то минимального значения, включать полосу прокрутки плюс добавляется выпадающий список:
Моё мнение, что прокрутка стимулирует создавать ещё больше вкладок, а так как с моей личной организованностью в этом плане дела обстоят не очень хорошо, то мне нужен внешний стимул, что бы заняться чисткой открытых страниц. Отсутствие визуального различия во вкладках (сильно налеплены) - хороший стимул в этом.
Корабль [космический] такое место, где любая потерянная вещь рано или поздно находится. Но это обычно не радует.
– Шумил Павел, “Три, четыре, пять, я иду искать”, цикл Окно контакта
PS а порекомендуйте годной космофантастики?
Буквально сегодня состоялся разговор по поводу того, что на GitLab Pages нет возможности автоматически обновлять сертификаты Let’s Encrypt (которые протухают каждые 90 дней) и что данная возможность есть на GitHub Pages.
Кроме того, сегодня как раз подошла череда обновления сертификата, заодно что-то меня потянуло поглядеть статью в документации GitLab по настройке интеграции с Let’s Encrypt: Let’s Encrypt for GitLab Pages
И что же я там вижу:
Let’s Encrypt for GitLab Pages (manual process, deprecated)
Warning: This method is still valid but was deprecated in favor of the Let’s Encrypt integration introduced in GitLab 12.1.
Воу! С радостным предчувствием иду по указанной ссылке и таки да, они завезли автообновление сертификатов!
Но если интересно, как это было сделано вручную, добро пожаловать под кат.
Очень полезный ресурс от Андрея Пономаренко ( тыц, тыц) как для разработчиков библиотек, так и для маинтейнеров разного рода софта. Позволяет мониторить изменения в API/ABI интерфейсах библиотек:
Вообще функционал ресурса достаточно богат и интересен:
Все доступные инструменты можно глянуть на странице Reports.
Инструменты, используемые для анализа можно изучить на странице Open Source. При помощи оных вполне можно организовать мониторинг изменений для вашего проекта или библиотеки.
С удивлением для себя обнаружил, что Homebrew, который использовал несколько раз для установки пакетов и сборки/портирования софта на macOS, вполне себе может использоваться и на Linux и даже в среде WSL на Windows:
В целом неплохо, но:
Второй пункт особенно полезен для создания воспроизводимых окружений для сборки софта с последующей дистрибуцией. В этом отношении MXE даёт фору: там попросту можно восстановить окружение используя номер коммита GIT.
Ну и для Windows я бы предпочёл окружение MSYS2 с pacman в качестве пакетного менеджера.
Но, оно может оказаться полезным для установки более свежего софта без прав администратора с возможностью быстро откатиться (просто удалить директорию с установленным барахлом) на всяких LTS дистрибутивах.
Ну точнее не совсем. Статичный сайт на то и статичный, что вся генерация производится где-то там. Но иметь возможность получить ссылку на файл для редактирования конкретной страницы - достаточно удобная вещь.
Пара Markdown конвертеров из простого текста и HTML (исходного текста):
Оба конвертера JS-онли, могут работать непосредственно из браузеров, исходники прилагаются:
Digi-Key предоставляет символы и корпуса для компонентов, которыми они торгуют в формате понятному для KiCAD. И выкладывают их на GitHub. Кроме того, есть символы и от некоторых партнёров (репозитории разделены).
Помимо этого они же опубликовали учебный курс по работе с KiCAD на YouTube.
Все подробности по ссылке ниже:
Проверка кросс-постинга.
Пост - мемориз.
Не всегда рисовать таблицы в Markdown разметке удобно, особенно добавлять/удалять колонки (со строками всё намного проще). Да и просто следить за соответствием вводимых данных конкретной колонке. И вот совершенно случайно набрёл на ресурс: Tables Generator
А конкретно: Markdown Tables Generator
В визуальной форме вводятся данные таблицы, потом нажимаем Generate и копируем полученный код в текст. Просто.
Для редактирования можно скопировать таблицу и импортировать её через “File → Paste table data…”, естественно при условии корректности данных. Кроме того, можно данные для таблицы импортировать из CSV (“File → Import CSV File…”), как работает эта функция я не проверял, скорее всего могут возникнуть проблемы с пробелами или разделителями.
Что ещё? Вообще там можно создавать таблицы не только в разметке Markdown, а в:
Схожие ресурсы: