Делал тут небольшую работку, писал программку, которая позволяла таскать линии по холсту и формировать по его данным потом xml файл в заданном формате, который потом превращался в уровень для игры. Заказчик просил ObjectivC и целевая платформа Mac OS X, на мой вопрос о критичности ObjectvC ответил - не суть, предложил написать на Qt4, тем самым покроем, одним махом, три платформы: Linux/Windows/Mac, но будет нуанс - я только примерно знаю как собирать под Mac, в общем, подумав - согласились.
Работу, естественно, я делал под Linux, проверил сборку для Windows (опять таки - кросскомпиляция). Показал результаты (сборку под Win32 и скапченый видеоролик работы в Linux), заказчику понравилось, дальше пошла очередь запуска на Mac OS X…
Первым делом был скачан Qt SDK 2010.05 - бронебойно, но зато всё сразу есть. Собрать получилось без проблем (были ворнинги у линковщика на лишние пути, указанные через атрибут -L, которые реально не существуют, но тут камень в огород создателям SDK). А вот дальше встал вопрос - а как запускать приложение на машинах где нет Qt4? Под windows/linux, в случае распространения бинарников, можно просто положить необходимые dll/so рядом и исполняемым файлов, но в Mac OS X они распространяются в виде бандла (директория с определённой структурой и суффиксом .app). Так вот, что бы собрать всё нужные библиотеки в бандл, разработчики Qt сделали утилиту macdeployqt, которую, после сборки, достаточно натравить на полученное приложение так:
macdeployqt helloworld.app
Тут человек с ником Ayoy, тоже озадачивался подобными вопросами, и рассмотрел более подробно. Так же, он столкнулся с тем, что если используются библиотеки/фреймворки которые используют Qt, после обработки macdeployqt они будут продолжать ссылаться на системные, а не те, что в бандле. Что бы это исправить он написал скрипт на перл, которые позволяет это исправлять:
http://gist.github.com/109674
Чуть позже поставлю в виртуалку Mac OS X, посмотрю, может на будущее буду сам делать бандлы, а ещё заинтересовала кросс-компиляция для макоси :)
Замечание 1: Qt Creator (одна из последних git сборок)
При включенном отображении Outline в левой панели, при работе появляются значительные тормоза даже на небольших проектах (при моих 1024Мб RAM и Atom 1.6Гц). Решение: выбрать другой режим, тем более что в значительный промежуток времени эта панель вообще не нужна (убирается и вновь показывается при помощи Alt-0), да и есть мощный инструмент Locate (Ctrl-K)
Замечание 2: sshfs и не уходим в sleep
Я активно пользуюсь sshfs для подключения удалённых ресурсов, удобно, быстро, не нужно дополнительных плясок. Недавно стал наблюдать, что система при каких-то условиях перестала засыпать на нетбуке. Опытным путем выяснилось условие: ресурс, примонтированный при помощи sshfs, был отлючен с использованием опции lazy у fusermount (иначе ругался на Resource busy). При этом продолжал висеть процесс sshfs, его убийство после, опять позволяло уводить систему в sleep.
Вышла версия 0.5.0 программы Crowns для построения проекций крон деревьев. Скачать можно
тут
В этой версии, основные изменения, касающиеся функционала в целом:
- Добавлена возможность удалять подложку из проекта.
- Добавлена возможность экспорта параметров крон деревьев в формат, пригодный для обработки в математических программах типа Octave (100% проверено), Scilab (проверено частично), Mathlab (теоретически должно работать). Т.к. проекции теперь строятся при помощи кривых Безье, то при экспорта с точностью 0.1 выдаются и промежуточные точки для построения полной проекции, теоретически, после обработки данные будут пригодны для загрузки в GIS.
- Исправлена ошибка, при которой подложка не удалялась при открытии проекта без оной или создании нового проекта.
- Исправлена ошибка, при которой случайное нажатие клавиши Esc приводило к закрытию окна программы.
Другие изменения, касающиеся технических аспектов разработки:
- Исправлены вспомогательный скрипты для отстройки и паковки win32 версии из среды Linux.
- Был осуществлен переход на систему сборки CMake.
- Исправлено не критическое поведение с float типами при сохранении проекта: значения сохранялись как @Variant(..).
Полный список изменений:
ChageLog
На правах мемориза.
Тут лежит полная и последняя:
http://gcc.gnu.org/onlinedocs/ в различных форматах, берём то, что нужно, а в системе пользуемся
инфо
А здесь полезная информация от гентоводов:
http://en.gentoo-wiki.com/wiki/Safe_Cflags - безопасные флаги оптимизация для различных процессоров (далее по тексту - ссылки)
Многим знакомо цветовое пространство RGB (Red/Green/Blue), мне потребовалось же работать с входными данными пространства YUV, которое широко используется в семействе кодеков MPEG.
Потребовалось тут собрать для C++Builder DLL, наткнулся походу на такой мануал:
http://bcbjournal.org/articles/vol4/0012/Using_Visual_C_DLLs_with_CBuilder.htm
В мемориз, хотя, надеюсь, оно мне никогда не пригодится, собирать под винду, это ужас…
Полезная ссылка:
http://my.opera.com/Lex1/blog/flashblock-for-opera-9/
даны различные рецепты, в том числе очень удобный для Opera 10.5+: просто включить опцию EnableOnDemandPlugin, для чего нужно открыть настройки: opera:config#UserPrefs|EnableOnDemandPlugin, опция автоматически добавится, и можно её включить. Да, это будет работать для любых плагинов.
Сама новость на OpenNet:
http://www.opennet.ru/opennews/art.shtml?num=27979
Рабочий эксплоит:
http://sota.gen.nz/compat2/robert_you_suck.c
PS рабочий, в смысле, что у меня сработал отлично :)
А в нем и моя очередная статья “QLandKarte GT как замена OziExplorer в GNU/Linux” (название откорректировано редактором, но не суть). Рассматривается вопрос использования данных, подготовленных для использования в OziExplorer (или созданных ими), коих на просторах интернетов премножество, в среде Linux, на примере QLandKarte GT.
Скачать:
http://osa.samag.ru/get/OpenSource068.zip
Стоимость (полная) перевода WM -> Alfa-click - 2.8%, обратно - 1%
Привязка осуществляется через Альфа-Клик, предварительно в WM нужно получить формальный аттестат (
http://passport.webmoney.ru), после чего нужно в секции “Мои документы” закачать сканы или снимки:
- разворота паспорта с фотографией
- разворота паспорта с пропиской
- ИНН
Дождаться, когда рядом с ними появятся зелёные значки, до тех пор Альфа-Клик будет ругаться на то, что вам нужно иметь формальный сертификат с подтвержденными паспортными данными.
Если возникнут проблемы, можно спросить в этой теме:
Привязка к Альфа-банку.
Из вышеуказанной темы, уверяют, что для сверки используется информация о номере паспорта и ФИО, так что следите, что бы они были корректными (я, при заполнении анкеты в банке, нашел несколько, в т.ч. в имени, так что будьте бдительны).
Несколько ссылок:
Те же самые операции с Яндекс.Деньгами прошли менее болезненно, при условии, что паспортные данные в системе ЯД уже предоставлены (там только ничего никуда не нужно сканировать и выкладывать)
Ну чтос, с праздничком!
В продолжении темы, поднятой мною тут: 906984
, таки решил озадачится, результатом озадачивания стало два скрипта.
-
gen-man2html.sh - пробегает по указанным секциям man-страниц (где они лежат и какие секции - внутри файла, лениво было опциями делать), и конвертирует их в HTML, заодно, по некоторым патернам создаёт ссылки (типа printf(3) или ссылкки в секцию 0, для <header.h>)
-
gen-html2assistant.sh - собственно уже пробегает по этим, сгенерированным, страницам, делает файл проекта справки Qt Assistan и, по завершении, вызывает *qhelpgenerator// для создания файла справки (на самом деле это SQLite база). После чего этот файл можно подключить в Qt Assistant:
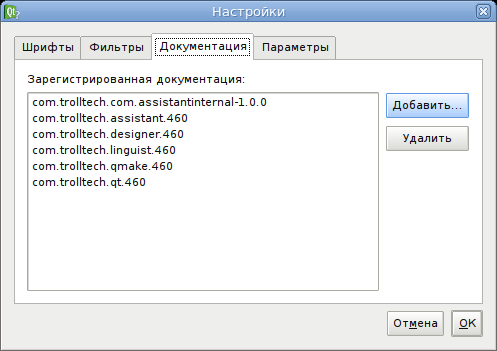
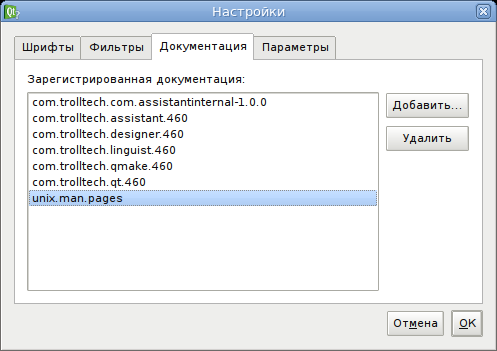
Для того, что бы к работал поиск в “Указателе”, нужно указывать ключевые слова, в данный момент, в качестве оных, используется имя самой страницы. Полнотекстовый поиск будет доступен в соответствуем месте в Qt Assistant после окончания генерации индекса. В “Содержании” добавится новый пункт “Unix man pages”.
Вот так вот примерно это дело выглядит:
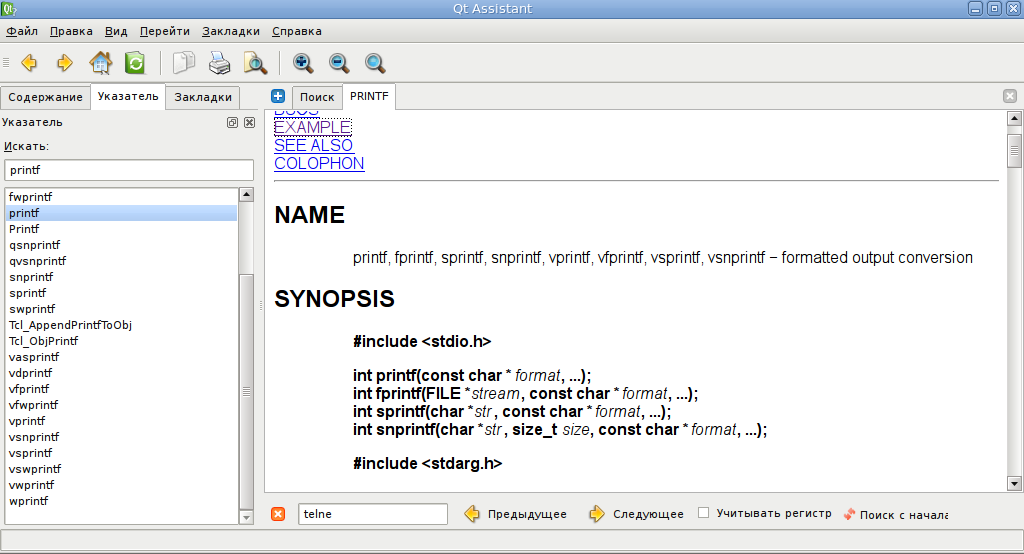
Сразу вопрос: подскажите инструмент для генерации ключевых слов для документа, интересует, на данный момент, только английский язык.
Бонусом нам это добавляет контекстную справку по всем функциям glibc и установленных библиотек (для которых есть man-page) в Qt Creator.
Сгенерированный мною файл справки можно взять тут:
http://hatred.homelinux.net/~hatred/unixman.qch.gz
UPD:
буквально сегодня в списке рассылки Qt Creator проскользнула статья:
Linux Man Pages integration with Qt Creator со схожим механизмом получения справочного файла. Отличие в том, что он брал готовые man-страницы в html с
http://www.kernel.org/doc/man-pages/online_pages.html
UPD2:
Там же в рассылке всплыла ссылка на галерею документации для Qt Creator:
https://wiki.qt.io/Qt_Creator_Documentation_Gallery (или поиском по “Qt_Creator_Documentation_Gallery”, так как они уже несколько раз домены тосовали).
В текущем состоянии не густо, но есть C++ Reference и убогенькая, сгенерированная doxygen документация по STL, а так же рекомендацию, как при помощи Doxygen генерировать документацию для Assistant.
Ещё когда топали на Ольховую, Ярослава кинула идею, что надо бы съездить на север Приморья, посетить водопад Чёрный Шаман (Большой Амгинский, высота около 30-35 метров - видимая часть и около 10-15 метров невидимая). Тогда дата была определена крайне расплывчато: а вот как нибудь в августе.
Узнал из
новости про очередной RC ядра Linux. А вот и пользовательская утилита:
http://pavlinux.ru/fanotify.tar.bz2, ну последней ссылкой, описание на LWN с небольшим примером на Си в конце:
http://lwn.net/Articles/339253/
Столкнулся с проблемой - никоим образом не получалось отредактировать контакт в ростере, хотя горячая клавиша была назначена. В конференции
psi-dev@conference.jabber.ru подсказали, посмотреть, а не залочен-ли ростер, оказалось - залочен, исправлять:
- Настройки -> Дополнительно
- далее находим опцию: options.ui.contactlist.lockdown-roster и ставим в true
Всё!