В менеджмент консоли:
all dump 1000
через некоторое время проверять логи медмент-ноды, там будут данные в процентах от выделенной памяти.
команда для разработчиков, по слову help про неё ничего не прочитаешь, а прочитаешь тут:
http://dev.mysql.com/doc/ndbapi/en/ndb-internals-dump-command-1000.html и про аналогичные команды также.
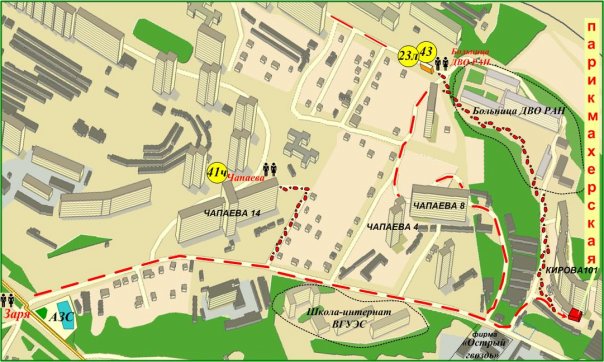
Моя бывшая одногрупница, примерно год назад стала обладательницей своего салона-парикмахерской, название которой “Надежда”. Месяц назад, на сборе нашей группы я об этом узнал, ну вот пришла пора подстригаться, решил поддержать своих так сказать.
Район конечно не топовый для размещения и большой популярности, но такие тихие местечки мне как раз и нравятся: расположена в районе остановки заря, не далеко от школы-интерната для одарённых детей, точный адрес: Кирова 101, парикмахерская “Надежда”. По меркам всяких обстановок и пр. не берусь судить, тут у меня вкус довольно червствый. В общем как подстригли понравилось, причем сказал - подстригите на свой вкус, оказалось почти так как обычно стригусь, мелочь, что прочувствовали, а приятно. Кроме того подравняли бороду, немного сменив стиль. И всё это добро вышло в 250 руб… ещё одна приятная мелочь. В общем - рекомендую ;)
Вот примерный план:
Хотел ещё завести давней знакомой её книжку и флешку, да по причине забытия телефона дома это дело обломилось, немного подумав, решил сгонять в Оахаку, выпить чашечку кофе. Блин, приятная кофейня в самом центре города, теплая уютная обстановка, приятная негромкая музыка, во втором зале фотоработы хозяина кофейни. Он кстати часто бывает там сам, думается интересный человек :simple_smile: Спасибо Танюхе (aka Sortis aka Азраэль) за то что в своё время показала это заведение ;)
Ну собственно кроме этого сестренке в комнате стеллаж для книжек поставили и посмотрел Белый клык, на этом день и уже подходит к концу, завтра топаю в горы, в компанию только одного человека из 10 кандидатов вытянуть получилось, ну да ладно, и один бы сходил =-)
Для начала, вышла версия 0.11.0, сайт программы:
http://www.qlandkarte.org/
Что из себя представляет, я
уже писал
И несколько заметок:
.
В общем, было уже давно мной замечено странное поведение в работе с интернетом с компов что сидят за маскарадингом в моей маленькой домашней сети. В чем это проявляется? А вот в чем: не через прокси практически невозможно серфить по WWW, открываются только единичные сайты, некоторые протоколы, конкретно столкнулся с git, не работают - просто висит соединение.
Схема подключения такая:
[компы сети]=====[свитч]------[роутер (inet via pppoe)]-------[ADSL модем]--~~~~~--[internet]
Анализ сетевых настроек ничего не дал, игры с MTU/MRU тоже, отключение ipv6 и windows scaling тоже, анализ работы tcpdump тоже… Поиск решения по интернету проводился долго и мучительно, но в итоге набрел на обсуждение:
http://www.usenet-forums.com/linux-networking/71513-iptables-adsl-some-protocols-not-working.html и на документацию:
http://www.linux.org/docs/ldp/howto/Adv-Routing-HOWTO/lartc.cookbook.mtu-mss.html
Результат - решение проблемы: добавить правило для iptables:
iptables -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
конкретно в моём случае они получились такими:
-A FORWARD -i eth1 -o ppp999 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
-A FORWARD -i ppp999 -o eth1 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
PS кстати, отключить ipv6 можно так: создать файлик /etc/modprobe.d/ipv6 со следующим содержимым:
Включаем
В продолжении ранее поднятой
темы
Покумекав по форумам нашел информацию, что на моём чипсете NCQ должен включаться параметром adma=1 модулю sata_nv, в первую очередь смутило то, что спросив modinfo sata_nv, мне было сказано, что опция включена по дефолту. Но мы обычно не верим, и проверяем.
Обновил DokuWiki до последней редакции. Заодно сменил темплейт на
r7throot5, в котором сходу пришлось подправить некоторые данные в rss, что бы с моими темами в системе оно было бы юзабельно (белый текст на белом фоне это конечно круто:))
/UPDATE/ если используется плагин Avatar: или обновите его так же, или вниметльно прочитайте на странице
http://www.dokuwiki.org/plugin:avatar касательно функции isvalidemail()
Цитата (
http://blog.kovyrin.net/2006/08/11/turn-on-ncq-on-ich-linux/#comment-4100):
SATA Native Command Queueing support
This is automatically enabled if both the controller and device
support NCQ. libata supports maximum of 31 concurrent commands. If
NCQ is enabled you should be able to see a message like the following
during device initialization.
ata1.00: ATA-7, max UDMA7, 312581808 sectors: LBA48 NCQ (depth 31/32)
If the device supports NCQ but the host doesn’t, you’ll get
ata8.00: ATA-7, max UDMA7, 312581808 sectors: LBA48 NCQ (depth 0/32)
Queue depth can be adjusted by
# echo 16 > /sys/class/scsi_device/0:0:0:0/device/queue_depth
But, there aren’t many good reasons to mess with queue depth.
У меня:
# dmesg | grep NCQ
ata3.00: 1465149168 sectors, multi 1: LBA48 NCQ (depth 0/32)
Теперь появился повод подумать… У кого нить есть какие предложения? Может на это влияет различные параметры SATA/IDE в BIOS?
PS версия драйвера sata_nv: 3.5, ядро 2.6.28.2
Strace - утилита для трассировки системных вызовов и сигналов. Часто бывает полезна в задаче определения какие файлы открывает программа за время своей работы, например, где ищет конфиги. На этом функционал не ограничивается, подробности можно посмотреть в странице руководства. Есть практически в любом дистрибутиве Linux.
Проблема: есть установленный Solaris 10 (SPARCv9), в зоне запущен memcached 1.2.6 (последний стабильный), через некоторое количество активных запросов к мемкешу он впадает в коматозное состояние - перестает отвечать вообще (подключения позволяет устанавливать, к примеру, тем же telnet’ом, но уже на запросы текстовым протоколом не даёт никакие ответы).
Решение: перекомпилить memcached без параметрета скрипта ./configure --enable-threads, после чего опция запуска -t будет недоступна. Баг memcached? Попробую в багтрак запостить.
Почти три дня ушло на поиск решения проблемы. Интернет по этому поводу вообще молчал.
Выбирал, выбирал, остановился на Brief:
https://addons.mozilla.org/en-US/firefox/addon/4578
Каждый со своими особенностями и прочим. Какие-то забыл? Комментируйте :)
-
lynx - наверное самый старый, потому и самый первый. Есть почти в любом дистрибутиве Linux, умеет дампить html в простой текст, что используется в mc для отображения html страничек по F3. Не умеет таблиц, что очень часто портит восприятие страницы. Фишек много, но не получилось сохранить капчу, которая в html задана в таком виде:
<img src="/confirm.php" alt="captcha" title="captcha" border="0"> Отобразился только альтернативный текст. Есть в репозитариях Arch Linux
-
links - старенький и уже не развивается, трудно найти в дистрибутивах уже, умеет таблички, не умеет, к примеру, HTTP аутентификации.
-
elinks - расширили links новыми возможностями, стал хорошим браузером, не без своих загонов конечно, капчу показанную выше позволил сохранить, что я потом посмотрел в zgv и ввел в браузере - прошло. Но дальше было ожидание до скачивания, сделанное на js, так что обломился :) Наличиствуется в репозитариях Arch Linux.
-
links2 - дальнейшее развитие links (кто бы дал умереть ему!?) научился работать в графическом режиме (links -g), научился http аутентификацию. С капчей вышеуказанной поступил как elinks. Таблицы и прочая радость и… практически невозможно работать из UTF8 терминала… ну заточен он на 8бит кодировки, так что юзаем luit. Он как и luit есть в резпозитариях Arch Linux.
-
Links Hacked - по сути - links2 + портирование некоторых фич из elinks. Остальное не юзал, не знаю.
-
w3m - наверное самое вкусное… первое что бросается в глаза - отлично работает с UTF8, а как же - разработчик японец, а там с кодировками почище нашего :) умет таблицы, умеет как и lynx дампить html, посему в конфиге mc и занял место lynx’а. Капчу отобразил мне как и lynx, т.е. прочесть не удалось. Есть в репозитариях Arch. Из вкусностей: w3mman - гипертекстовый навигатор по man страницам, в секции See also подствечивает гиперссылками страницки на которые можно перейти - удобно :) Главное меню вызывается по клавише Ins
Да, все браузеры не умеют java script, для w3m наткнулся на это:
http://abe.nwr.jp/w3m/w3m-js-en.html но вроде как не жизнеспособно.
Если DNS провайдера подгоняет, или висит, или у вас несколько линков в Internet, которые переключаются в зависимости от доступности, а DNS провайдера отвечает только в том случае, если с его адресов запрос пришел (Привет Дальсвязи! И спасибо
НТК, что отвечают не только своим адресам). Собственно выход - использовать нейтральный DNS сервис. Один из таких (в Техлайн Транстелеком их выдал на запрос :)) - OpenDNS.
Сайт сервиса:
http://www.opendns.com
Первичный и вторичный DNS:
- resolver1.opendns.com: 208.67.222.222
- resolver2.opendns.com: 208.67.220.220
Собственно только недавно начал собирать информацию, как в отсутствии винды и доса прошить BIOS, и вот уже ответ:
flashrom. Сам пока не тестировал, svn версия лежит в у ArchLinux в AUR:
http://aur.archlinux.org/packages.php?ID=23390
По результатам отпищусь позже :)
На заметку, без особой гибкости, но…
В общем команда:
dd if=/dev/urandom count=128 | uuencode - | mkpasswd -s
выдаст примерно следующее:
OvdDK0TV8FZQY
или, вариация:
dd if=/dev/urandom count=128 | uuencode - | mkpasswd -s -m md5
выдаст примерно следующее:
$1$cIpngJsx$LT.EpSQS3rEQPfAeBCDhI1
поднобности:
mkpasswd –help
mkpasswd -m help
man mkpasswd
Да, вообще mkpasswd генерирует хеш последовательности… но :)
UPD:
На моей ArchLinux машинке mkpasswd утилита находится в пакете expect и работает значительно проще:
$ mkpasswd
js2ts4TG"
Длинну сгенерированной последовательности можно задать при помощи параметра -l __число__. Посмотреть какие параметры он понимает штатным образом не предоставляется возможнным, автор скрипта (да, это скрипт на tcl) не предусмотрел такой возможности :) Потому, кому интересно, - смотрим сам скрипт.